Friday, December 08, 2006
Tuesday, December 05, 2006
Explorers and the Game of Tag
I'm partial to games of exploration. The Ultimas and their relatives were my early favorites. These days, I play games like Grand Theft Auto, Godfather, Spider-Man 2 and Oblivion.
Why? It's the joy of discovery - the pleasure of finding things out. So what makes a great open world game? In the context of video games, an open world is a toy upon which a game can be built. So first, what makes a great open world?
Big, not too big
It's no secret that we measure the size of our universe in the time it takes to cross it. The world shrinks with the inventions of the railroad, the automobile and the airplane. Unlike other open world games, the world of Superman Returns seems in turns enormous and tiny, depending on whether you are walking or flying at supersonic speeds. When a world is too big, we can spend all of our time simply getting around. Too small and it seems cramped and unimaginitive.
There must be some novelty to every distinct area or region. The 1987 game The Faery Tale sported a world of over 17,000 screens. There were so many repeating patterns of landscape and it took so long to cross that it was hard to stay interested in exploring the world. In an interview with Game Informer, Radical, in creating Hulk: Ultimate Destruction, specifically addressed this issue of variety.
Mechanics
The mechanics of a world are crucial to its experience. They are the laws of the game's universe. It is important that the game itself cannot subvert these rules. In GTA, this includes the way cars move collide and interact, that any car can be rigged with bombs and the general behavior of the people and objects that inhabit Liberty City. Another important mechanic in GTA is police response to player actions. The world of GTA is rich with mechanics largely orthogonal in purpose. It is this richness that makes GTA great. In Spider-Man 2, the central mechanic is web-swinging. The world of Spider-Man 2 is designed to be experienced through web-swinging and so it is an inseparable element of Treyarch's Manhattan. In GTA, Spider-Man 2 and Superman Returns the speed at which one is able to move through the city is variable and its 8control is in some mechanic anchored in the game world itself. This provides a sense of enormous freedom. In some of these games, this speed increases as the player progresses through the game.
Even so, at this level, the open world is still a toy. Now let's ask the question, what makes a great open world game?
The Childhood Game of Tag
Of course, GTA 3 is the prototypical open world game. Recently, I started playing it yet again and it still may be the best. What makes it fun? The underlying element is tag. The ancient children's game is incredibly simple, infinitely flexible and has strategic depth. Tag benefits from richness and complexity in a large world. The ideal tag world has nooks and crannies in which to hide from predators and from which to ambush prey. Layered on top of that, in GTA, there a number of other game mechanics, many - most? - of which are themselves variations on tag.
These layers of tag and alternating roles of hunter and hunted in GTA 3 stand in contrast to Spider-Man 2's races which also aim to capitalize on a large in-game world. Unfortunately, racing is much less fun than tag. Even though it's one of my favorite games, Spider-Man's races don't appeal to me. What appeals to me about Spider-Man 2 is the absolute euphoria of swinging and the crazy missions (levels?) like Mysterio's burning theater and the Statue of Liberty.
Tag (from Wikipedia)
Players: 2+
Rules complexity: Low
Strategy depth: High
Random chance: Low
Skills required: Running, Hiding, Observation
Why? It's the joy of discovery - the pleasure of finding things out. So what makes a great open world game? In the context of video games, an open world is a toy upon which a game can be built. So first, what makes a great open world?
Big, not too big
It's no secret that we measure the size of our universe in the time it takes to cross it. The world shrinks with the inventions of the railroad, the automobile and the airplane. Unlike other open world games, the world of Superman Returns seems in turns enormous and tiny, depending on whether you are walking or flying at supersonic speeds. When a world is too big, we can spend all of our time simply getting around. Too small and it seems cramped and unimaginitive.
There must be some novelty to every distinct area or region. The 1987 game The Faery Tale sported a world of over 17,000 screens. There were so many repeating patterns of landscape and it took so long to cross that it was hard to stay interested in exploring the world. In an interview with Game Informer, Radical, in creating Hulk: Ultimate Destruction, specifically addressed this issue of variety.
Mechanics
The mechanics of a world are crucial to its experience. They are the laws of the game's universe. It is important that the game itself cannot subvert these rules. In GTA, this includes the way cars move collide and interact, that any car can be rigged with bombs and the general behavior of the people and objects that inhabit Liberty City. Another important mechanic in GTA is police response to player actions. The world of GTA is rich with mechanics largely orthogonal in purpose. It is this richness that makes GTA great. In Spider-Man 2, the central mechanic is web-swinging. The world of Spider-Man 2 is designed to be experienced through web-swinging and so it is an inseparable element of Treyarch's Manhattan. In GTA, Spider-Man 2 and Superman Returns the speed at which one is able to move through the city is variable and its 8control is in some mechanic anchored in the game world itself. This provides a sense of enormous freedom. In some of these games, this speed increases as the player progresses through the game.
Even so, at this level, the open world is still a toy. Now let's ask the question, what makes a great open world game?
The Childhood Game of Tag
Of course, GTA 3 is the prototypical open world game. Recently, I started playing it yet again and it still may be the best. What makes it fun? The underlying element is tag. The ancient children's game is incredibly simple, infinitely flexible and has strategic depth. Tag benefits from richness and complexity in a large world. The ideal tag world has nooks and crannies in which to hide from predators and from which to ambush prey. Layered on top of that, in GTA, there a number of other game mechanics, many - most? - of which are themselves variations on tag.
These layers of tag and alternating roles of hunter and hunted in GTA 3 stand in contrast to Spider-Man 2's races which also aim to capitalize on a large in-game world. Unfortunately, racing is much less fun than tag. Even though it's one of my favorite games, Spider-Man's races don't appeal to me. What appeals to me about Spider-Man 2 is the absolute euphoria of swinging and the crazy missions (levels?) like Mysterio's burning theater and the Statue of Liberty.
Tag (from Wikipedia)
Players: 2+
Rules complexity: Low
Strategy depth: High
Random chance: Low
Skills required: Running, Hiding, Observation
UML's Accidental Complexity
Accidental complexity is the complexity imposed by a given approach (in this case, a language) to solving a problem as opposed to an essential complexity of the problem itself. Recently, I documented a system I'd developed for a presentation for my coworkers. I diagrammed the class relationships in UML in Visio. Then I started swearing as I always do whenever I use UML. Now don't get me wrong, I enjoy UML and it's a valuable and useful tool when its limitations are understood.
So why does UML make me swear when I use it?
These goals of a UML design are irrelevant to the original language implementation. And, of course, the implementation language will have its own accidental complexity whose concerns must take higher precedence. Nevertheless, readability is important. An unreadable UML diagram is a waste of everyone's time.
What effect does UML representation have in describing software designs? Since subclassing allows classes to inherit lines of association from their parents while containment does not, readable UML favors subclassing over containment/composition which, in C++ based object oriented languages (such as C++, Java and C#), is inappropriate and even wrong (later, an entry on subclassing vs. containment).
Below, an artificial abstract class is introduced to tame UML complexity. Keep in mind that this diagram represents a very simple design.
Before -

After -

The first diagram resembles an electrical circuit and its suffers from the same difficult problem - complex, multidimensional relationships flattened to a two-dimensional plane. In the second, we introduce a false abstract class simply to preserve readability.
Clearly, readable UML representation as a requirement for software design is not a useful constraint - especially when it degrades the quality of a software system. This is an issue that must be understood when using UML to design or present software systems.
So why does UML make me swear when I use it?
- UML is graphical and two-dimensional.
- A UML design should be readable, preferrably at a glance without too much study.
- UML is general, intended to apply with equal descriptiveness to multiple object-oriented languages.
These goals of a UML design are irrelevant to the original language implementation. And, of course, the implementation language will have its own accidental complexity whose concerns must take higher precedence. Nevertheless, readability is important. An unreadable UML diagram is a waste of everyone's time.
What effect does UML representation have in describing software designs? Since subclassing allows classes to inherit lines of association from their parents while containment does not, readable UML favors subclassing over containment/composition which, in C++ based object oriented languages (such as C++, Java and C#), is inappropriate and even wrong (later, an entry on subclassing vs. containment).
Below, an artificial abstract class is introduced to tame UML complexity. Keep in mind that this diagram represents a very simple design.
Before -
After -
The first diagram resembles an electrical circuit and its suffers from the same difficult problem - complex, multidimensional relationships flattened to a two-dimensional plane. In the second, we introduce a false abstract class simply to preserve readability.
Clearly, readable UML representation as a requirement for software design is not a useful constraint - especially when it degrades the quality of a software system. This is an issue that must be understood when using UML to design or present software systems.
Monday, December 04, 2006
On Reference Counting
Reference counting is one of those nasty little things that always seems easy and straightforward before you do it and for which you always curse yourself afterward. There is often little choice (so don't curse yourself too much) because in many circumstances it's the lesser of two evils. The other evil is full blown garbage collection - arghh..! Remember, if there's a good way to restructure your code to eliminate the need for ref-counting or garbage collection, DO IT!
I have code that I use whenever I decide to ref-count that allows me to monitor object lifetimes, object ages and so forth to easily debug ref-counting issues. It requires extra memory and so is not suitable in every case. Alternatively, I've simply logged object creation and deletion to a file and then written a separate program to read the log to locate the offending objects and the general regions of code responsible for creating and (not) deleting them.
But don't ever assume that ref-counting bugs will be easily fixed. Usually once you fix one symptom another one pops up somewhere completely removed from the first. Both are probably unrelated to the source of the problem. This is what makes ref-counting insidious. So take my advice, when implementing ref-counting, do your due diligence upfront and make sure every increment and decrement is accounted for. You'll be sorry if you don't.
I have code that I use whenever I decide to ref-count that allows me to monitor object lifetimes, object ages and so forth to easily debug ref-counting issues. It requires extra memory and so is not suitable in every case. Alternatively, I've simply logged object creation and deletion to a file and then written a separate program to read the log to locate the offending objects and the general regions of code responsible for creating and (not) deleting them.
But don't ever assume that ref-counting bugs will be easily fixed. Usually once you fix one symptom another one pops up somewhere completely removed from the first. Both are probably unrelated to the source of the problem. This is what makes ref-counting insidious. So take my advice, when implementing ref-counting, do your due diligence upfront and make sure every increment and decrement is accounted for. You'll be sorry if you don't.
Inline Assembly
On my current project I will soon delve into optimization tasks at the level of inline assembly for PowerPC. These days the use of inline assembly is almost never justified. It's about as unportable as code can be and it's nearly impossible to understand once it's written. Most of the time, unless you devote a great deal of energy or unless you are using processor features (SIMD, for example) inaccessible through C or C++, hand-written assembly will actually be slower than compiler generated code. Furthermore, most of what you learned a few years ago about optimizing assembly code simply does not hold any more. For example, what's the faster way to multiply an integer by 5 on the x86?
A. x = (x << 2) + x;
or
B. x *= 5;
Old school assembly says that A is faster. Not true anymore. The imul (integer multiply) instruction is as fast as a single shift on the x86 these days. Counting cycles? Hard to do these days with deep pipelines, instruction reordering, branch prediction and unpredictable memory latency. The most effective way to optimize assembly seems to be aggressive profiling and trial and error. Gone are the days when you can optimize code by counting cycles with the processor manual tables in hand. Even so, these guidelines are important:
1. Most importantly, make sure you have the most efficient algorithm possible for the job before moving to assembly! There are a million good reasons for this and nothing could be more embarrassing than having your finely tuned assembly bubble sort owned by a C (or Java!) mergesort written in 12 minutes.
2. Profile changes aggressively and with the finest resolution (usually the CPU cycle counters) possible.
3. Space out memory accesses. Because of memory latency (and asynchronous memory access), you can hide cycles between your memory reads and writes.
4. Know your memory access patterns and take advantage of them. Do you only write and never read back from certain areas of memory? It may be beneficial to write-through directly to memory and avoid caching. It can also be useful to prefetch memory in certain cases.
5. Keep your data structures small enough to fit completely in cache. This will yield enormous benefits if you can do it.
6. Use SIMD where appropriate. This can give great benefit and itself may justify moving to inline assembly. However, don't spend an excessive number of cycles trying to fit data into SIMD-ready structures. It'll probably cost more than you'll get from it. Use SIMD when it's a good fit.
7. Unroll loops - to a point. Unroll tiny loops until they no longer provide a performance benefit. Keep unrolling and profiling. When you've gone too far you'll see a significant performance drop as that piece of code outgrows the instruction cache. If you have enough information on the hardware, you can figure out where this threshold will be.
8. On PC use SIMD for 64-bit integer arithmetic instead of the atrocious code that's generated for this by Visual C++.
Just so you know, this entry is subject to revision. Have any other guidelines? Let me know about 'em!
A. x = (x << 2) + x;
or
B. x *= 5;
Old school assembly says that A is faster. Not true anymore. The imul (integer multiply) instruction is as fast as a single shift on the x86 these days. Counting cycles? Hard to do these days with deep pipelines, instruction reordering, branch prediction and unpredictable memory latency. The most effective way to optimize assembly seems to be aggressive profiling and trial and error. Gone are the days when you can optimize code by counting cycles with the processor manual tables in hand. Even so, these guidelines are important:
1. Most importantly, make sure you have the most efficient algorithm possible for the job before moving to assembly! There are a million good reasons for this and nothing could be more embarrassing than having your finely tuned assembly bubble sort owned by a C (or Java!) mergesort written in 12 minutes.
2. Profile changes aggressively and with the finest resolution (usually the CPU cycle counters) possible.
3. Space out memory accesses. Because of memory latency (and asynchronous memory access), you can hide cycles between your memory reads and writes.
4. Know your memory access patterns and take advantage of them. Do you only write and never read back from certain areas of memory? It may be beneficial to write-through directly to memory and avoid caching. It can also be useful to prefetch memory in certain cases.
5. Keep your data structures small enough to fit completely in cache. This will yield enormous benefits if you can do it.
6. Use SIMD where appropriate. This can give great benefit and itself may justify moving to inline assembly. However, don't spend an excessive number of cycles trying to fit data into SIMD-ready structures. It'll probably cost more than you'll get from it. Use SIMD when it's a good fit.
7. Unroll loops - to a point. Unroll tiny loops until they no longer provide a performance benefit. Keep unrolling and profiling. When you've gone too far you'll see a significant performance drop as that piece of code outgrows the instruction cache. If you have enough information on the hardware, you can figure out where this threshold will be.
8. On PC use SIMD for 64-bit integer arithmetic instead of the atrocious code that's generated for this by Visual C++.
Just so you know, this entry is subject to revision. Have any other guidelines? Let me know about 'em!
Saturday, December 02, 2006
Experimental Gameplay
I met Kyle Gray yesterday who sits a couple of rows away from me at work and runs a fascinating site called the Experimental Gameplay Project. If you are at all interested in game play, check it out.
Some of my favorites so far are Hovercrafty, Pluto Strikes Back and Big Vine. Maybe around Christmas when I've got a little time off, I'll make a game or two.
Some of my favorites so far are Hovercrafty, Pluto Strikes Back and Big Vine. Maybe around Christmas when I've got a little time off, I'll make a game or two.
Tuesday, November 28, 2006
Some People I've Met (and Some People I Haven't) Whose Work I Like
Earlier I mentioned Richard Garriott as someone I'd like to meet. Jamie Fristrom emailed in response to that and sent this interesting story.
In junior high, I discovered Hackers, by Steven Levy which I must have read a dozen times. Steve Wozniak became my hero. I wanted to build computers.
Then it was games. I wrote to all of the programmers who converted Times of Lore to PC asking how they accomplished the overhead scrolling over the massive world. Herman Miller responded with a detailed description in C and assembly and recommended that I get the Programmer's Guide to PC and PS/2 Video Systems which I guess is going for $0.24 on Amazon these days. Armed with that information, the book and Turbo C, I started writing games like crazy.
So in college, a friend, Alex Kapadia, and I conceived a game called Undead: The Tibovian Era. I sent an early copy to the fast-growing shareware company Epic MegaGames and a few days later, received an excited phone call from the now legendary (in game circles) Tim Sweeney. Tim sent me an email (which in those days I dutifully checked on the Vaxen at UMKC) saying, "I'm looking forward to seeing more of Undead! It's the best 'first' game any author has shown us." Not bad, eh? This was a year or two before Unreal and I like to believe that my Undead inspired the similar name of Tim's magnum opus. Who knows..
Instead of finishing Undead, I spent a few years in Mexico. Kids these days. When I returned to Kansas City I found employment for a while doing bilingual customer service at a well known electronics company. At that time, I found myself sitting across the aisle from Niki Sullivan, one of the original members of Buddy Holly's Crickets! In his honor, the call center played nothing but Buddy Holly. Like an idiot, in my months there I was too awestruck to ever ask him anything about the days he wandered around the country participating in some of the seminal moments of American pop music.
And, of course, I've met a number of equally talented people in places I've worked such as Keane, VML, H&R Block, Sprint and EA Tiburon.
Without further reflection, that's the story of some people I've met (and some people I haven't) whose work I like.
In junior high, I discovered Hackers, by Steven Levy which I must have read a dozen times. Steve Wozniak became my hero. I wanted to build computers.
Then it was games. I wrote to all of the programmers who converted Times of Lore to PC asking how they accomplished the overhead scrolling over the massive world. Herman Miller responded with a detailed description in C and assembly and recommended that I get the Programmer's Guide to PC and PS/2 Video Systems which I guess is going for $0.24 on Amazon these days. Armed with that information, the book and Turbo C, I started writing games like crazy.
So in college, a friend, Alex Kapadia, and I conceived a game called Undead: The Tibovian Era. I sent an early copy to the fast-growing shareware company Epic MegaGames and a few days later, received an excited phone call from the now legendary (in game circles) Tim Sweeney. Tim sent me an email (which in those days I dutifully checked on the Vaxen at UMKC) saying, "I'm looking forward to seeing more of Undead! It's the best 'first' game any author has shown us." Not bad, eh? This was a year or two before Unreal and I like to believe that my Undead inspired the similar name of Tim's magnum opus. Who knows..
Instead of finishing Undead, I spent a few years in Mexico. Kids these days. When I returned to Kansas City I found employment for a while doing bilingual customer service at a well known electronics company. At that time, I found myself sitting across the aisle from Niki Sullivan, one of the original members of Buddy Holly's Crickets! In his honor, the call center played nothing but Buddy Holly. Like an idiot, in my months there I was too awestruck to ever ask him anything about the days he wandered around the country participating in some of the seminal moments of American pop music.
And, of course, I've met a number of equally talented people in places I've worked such as Keane, VML, H&R Block, Sprint and EA Tiburon.
Without further reflection, that's the story of some people I've met (and some people I haven't) whose work I like.
Wednesday, September 13, 2006
Speech Impediment
(Updated 7/10/07)
Lisp (and to a lesser degree, Scheme) fascinates me. Simple in the extreme and yet incredibly powerful, it is a thing of beauty. I learned Lisp by writing Lisp interpreters and compilers - usually to embed in other applications. As an embedded language Lisp excels - it is among the easiest languages to implement. Implementing it well, however, is an altogether different proposition.
By programming language standards, Lisp (1958) is an ancient tongue. It is older than COBOL by a year and older than C by more than a decade. And it is timeless.
Don't laugh but it's the coolest thing to build a tiny and reasonably fast Lisp bytecode VM (Pair, a current project of mine that I never get to, weighs in at a mere 28K!) and then shove it inside some application and make it do all sorts of things machines were never supposed to. Like thinking, for example :).
Lisp & Scheme
muSE - Embeddable Scheme dialect and more importantly, its associated blog.
Lambda The Ultimate Programming Languages Weblog
Elk
Some Favorite Lisp and Scheme Books
Paradigms of Artificial Intelligence Programming: Case Studies in Common Lisp
Lisp in Small Pieces - Great for building Lisp interpreters and compilers.
On Lisp
Lisp
Structure and Interpretation of Computer Programs - Don't buy this classic though - it's free online.
Lisp (and to a lesser degree, Scheme) fascinates me. Simple in the extreme and yet incredibly powerful, it is a thing of beauty. I learned Lisp by writing Lisp interpreters and compilers - usually to embed in other applications. As an embedded language Lisp excels - it is among the easiest languages to implement. Implementing it well, however, is an altogether different proposition.
By programming language standards, Lisp (1958) is an ancient tongue. It is older than COBOL by a year and older than C by more than a decade. And it is timeless.
Don't laugh but it's the coolest thing to build a tiny and reasonably fast Lisp bytecode VM (Pair, a current project of mine that I never get to, weighs in at a mere 28K!) and then shove it inside some application and make it do all sorts of things machines were never supposed to. Like thinking, for example :).
Lisp & Scheme
muSE - Embeddable Scheme dialect and more importantly, its associated blog.
Lambda The Ultimate Programming Languages Weblog
Elk
Some Favorite Lisp and Scheme Books
Paradigms of Artificial Intelligence Programming: Case Studies in Common Lisp
Lisp in Small Pieces - Great for building Lisp interpreters and compilers.
On Lisp
Lisp
Structure and Interpretation of Computer Programs - Don't buy this classic though - it's free online.
Tuesday, August 22, 2006
Let Me Count The Ways (Part II)
In the Sieve of Eratosthenes post, I mentioned that at work (EA) we have an optional programming challenge every once in a while. It was started last year by Jim Hejl and it's called Hacker's Delight - named after the excellent book of programming tricks by Henry S. Warren.
I love this stuff. Why? Who knows? Anyhow, this time I wrote the challenge - Hacker's Delight #6. I chose the { 64 choose 4 } problem from Let Me Count The Ways. My fast solution was initially ~3.9ms. Since I had not yet aggressively optimized it, I did that and got it down to ~2.5ms. That solution was written completely in C++. I figured that was about as fast as it got because it turned out that ~2.5ms is (slightly) faster than memset(data, 0, 635376 * sizeof(unsigned __int64)) !!
In short order, solutions came in that were almost exactly as fast as mine with quite different algorithms. Hmm. I thought, the bottleneck is memory-processor bandwidth - ~2.5ms is simply how long it takes to write 4.8mb of data. All the other processing is swamped by that.
Even so, Jim was experimenting with SIMD approaches and had an SSE version of 'memset' that executed in about half memset's time. I started playing with that but couldn't figure out how to use that to get better performance out of my algorithm.
Then Jim tells me that he received an entry from EA United Kingdom that executes in ~1.25ms - all SIMD (MMX)! The gauntlet is down. I asked him not to forward it to me or let me see it.
So today I finally got my own MMX version to about ~1.25ms. It seems to execute slightly faster than Jim's SSE memset. While minor speed improvements may be possible (on the order of tenths of milliseconds), I'm convinced that there's no way to get significantly faster performance.
I could be wrong.
When it's all over, I will post a more detailed description of the optimization steps for those of you who are interested. For those who are not, z z z z z z z z z z...
[The related, and more detailed document Optimizing 64 Choose 4 (.pdf)]
I love this stuff. Why? Who knows? Anyhow, this time I wrote the challenge - Hacker's Delight #6. I chose the { 64 choose 4 } problem from Let Me Count The Ways. My fast solution was initially ~3.9ms. Since I had not yet aggressively optimized it, I did that and got it down to ~2.5ms. That solution was written completely in C++. I figured that was about as fast as it got because it turned out that ~2.5ms is (slightly) faster than memset(data, 0, 635376 * sizeof(unsigned __int64)) !!
In short order, solutions came in that were almost exactly as fast as mine with quite different algorithms. Hmm. I thought, the bottleneck is memory-processor bandwidth - ~2.5ms is simply how long it takes to write 4.8mb of data. All the other processing is swamped by that.
Even so, Jim was experimenting with SIMD approaches and had an SSE version of 'memset' that executed in about half memset's time. I started playing with that but couldn't figure out how to use that to get better performance out of my algorithm.
Then Jim tells me that he received an entry from EA United Kingdom that executes in ~1.25ms - all SIMD (MMX)! The gauntlet is down. I asked him not to forward it to me or let me see it.
So today I finally got my own MMX version to about ~1.25ms. It seems to execute slightly faster than Jim's SSE memset. While minor speed improvements may be possible (on the order of tenths of milliseconds), I'm convinced that there's no way to get significantly faster performance.
I could be wrong.
When it's all over, I will post a more detailed description of the optimization steps for those of you who are interested. For those who are not, z z z z z z z z z z...
[The related, and more detailed document Optimizing 64 Choose 4 (.pdf)]
Thursday, June 08, 2006
Some Perfect Hash
The computer science department of the University of Alberta in Edmonton researches Artificial Intelligence (AI) for Poker. From their site I came upon Cactus Kev's Poker Hand Evaluator which is a killer fast five card hand evaluator. Reading through his algorithm you'll notice that the last step for any yet unclassified hand is a binary search through a list of values. Most hands end up in that search which is the most time-consuming part of the algorithm.
An Optimization
Replacing the binary search with a precomputed perfect hash for the 4888 values in the list yields a significant improvement over the original. The original test code included with Kevin's source (using eval_5hand) runs in 172 milliseconds on my machine and with my eval_5hand_fast it runs in 63 milliseconds. Yay, an improvement of 2.7 times!
fast_eval.c
(Updated 7/10/07)
This post has garnered a bit of attention. Cactus Kev added a comment and a link on his site back to the post and I've had an email conversation with a programmer (anonymous unless he's cool if I mention him) who ported the code to C# and reports:
Kev: 159ms
Your mod: 66ms
My C# version of your mod: 88ms
Pointers for seven hand evaluation? Check out the post 7.
An Optimization
Replacing the binary search with a precomputed perfect hash for the 4888 values in the list yields a significant improvement over the original. The original test code included with Kevin's source (using eval_5hand) runs in 172 milliseconds on my machine and with my eval_5hand_fast it runs in 63 milliseconds. Yay, an improvement of 2.7 times!
fast_eval.c
(Updated 7/10/07)
This post has garnered a bit of attention. Cactus Kev added a comment and a link on his site back to the post and I've had an email conversation with a programmer (anonymous unless he's cool if I mention him) who ported the code to C# and reports:
Kev: 159ms
Your mod: 66ms
My C# version of your mod: 88ms
Pointers for seven hand evaluation? Check out the post 7.
Sieve of Eratosthenes
At work we had a little challenge in December to see who could come up with a program to count the number of primes between any two numbers (0 to 2^32-1 inclusive) as fast as possible. To this end I wrote this optimized Sieve of Eratosthenes (algorithm) that counts all the primes from 0 to 4,294,967,295 in about 13.75 seconds on my (admittedly fast) development machine at work.
If you come up with any improvements to it, let me know!
(2/2/2007 - I'm going to go ahead and add the link for the multicore Sieve of Eratosthenes here. On a 3GHz dual core Xeon, 7.15s!)
If you come up with any improvements to it, let me know!
(2/2/2007 - I'm going to go ahead and add the link for the multicore Sieve of Eratosthenes here. On a 3GHz dual core Xeon, 7.15s!)
Friday, June 02, 2006
Let Me Count The Ways
Lately, I've been tinkering with card games (poker) a bit and one of the little questions that came up was what is the fastest way to enumerate all possible combinations of 4 items out of a possible 64? Actually, it doesn't have to be 4 of 64, it could be 7 of 48, or 2 specific aces from 52 cards or 3 bits of 10. The field of combinatorics can tell us how many there are. This is expressed as { n choose r } and has the formula factorial(n) / (factorial(r) * factorial(n - r)). In the case of n = 64 and r = 4 it yields 635,376 different combinations.
So, the task is to enumerate each of these unique combinations exactly one time until all 635,376 have been generated. This is one of those problems where the right approach makes all the difference.
The Naive Approach
Let's look, for a moment, at the most basic brute force approach: iterate through every value that can be contained in 64 bits and check if it has four bits. How long would this take? On my machine it takes 1 second to check 250 million numbers. Pretty fast, right? At this rate, however, it will take 2,340 years to check all 2^64 numbers! Clearly not a usable solution.
A Better Approach
Poking around the internet I found a function that takes a number and returns the next highest number with the same number of bits. I adapt it a bit and bam!
This variation turns in 32 milliseconds for complete enumeration. Not a bad improvement over 2,340 years, eh?
The Best Approach
I actually developed the following function before the above. However, I figured (from looking at the code) that the above would blow this one away. How wrong I was. One problem with the above approach is that it has a nasty little division. Another thing is that this approach takes advantage of certain special cases like when r == 1 and n == r. The following approach is based on my initial recursive approach, but I removed the recursion so that I could rewrite it as an iterator. Removing the recursion did not seem to have a significant impact on performance. Anyhow the following runs to completion in just 3 milliseconds, over 10 times faster than the above version.
So, the task is to enumerate each of these unique combinations exactly one time until all 635,376 have been generated. This is one of those problems where the right approach makes all the difference.
The Naive Approach
Let's look, for a moment, at the most basic brute force approach: iterate through every value that can be contained in 64 bits and check if it has four bits. How long would this take? On my machine it takes 1 second to check 250 million numbers. Pretty fast, right? At this rate, however, it will take 2,340 years to check all 2^64 numbers! Clearly not a usable solution.
A Better Approach
Poking around the internet I found a function that takes a number and returns the next highest number with the same number of bits. I adapt it a bit and bam!
int enumerate_combinations(int n, int r, unsigned __int64 *v)
{
unsigned __int64 y, r, x;
unsigned count = (unsigned)math::choose(n, r);
v[0] = ((unsigned __int64)1 << r) - 1;
for (unsigned i = 1; i < count; i++)
{
x = v[i - 1];
y = x & -(__int64)x;
r = x + y;
v[i] = r | (((x ^ r) >> 2) / y);
}
return count;
}
This variation turns in 32 milliseconds for complete enumeration. Not a bad improvement over 2,340 years, eh?
The Best Approach
I actually developed the following function before the above. However, I figured (from looking at the code) that the above would blow this one away. How wrong I was. One problem with the above approach is that it has a nasty little division. Another thing is that this approach takes advantage of certain special cases like when r == 1 and n == r. The following approach is based on my initial recursive approach, but I removed the recursion so that I could rewrite it as an iterator. Removing the recursion did not seem to have a significant impact on performance. Anyhow the following runs to completion in just 3 milliseconds, over 10 times faster than the above version.
template <typename T = unsigned __int64>
int enumerate_combinations(int n, int r, T *v)
{
struct { int n, r; T h; } s[sizeof(T) * 8] = { { n, r, 0 } }, q;
int si = 1, i = 0;
T one = 1;
while (si)
{
q = s[--si];
tail:
if (q.r != 0)
{
one = 1;
if (q.r == 1)
{
for (int j = 0; j < q.n; j++)
{
v[i++] = q.h | one;
one <<= 1;
}
}
else if (q.r == q.n)
{
v[i++] = q.h | (one << q.n) - 1;
}
else
{
--q.n; s[si++] = q; q.r--;
q.h |= one << q.n;
goto tail;
}
}
}
return i;
}
Tuesday, May 30, 2006
The Elder Scrolls IV: Oblivion
This weekend I sprung for an Xbox 360. Finally. Then I rented The Elder Scrolls IV: Oblivion. I'll have to take it back to Blockbuster Thursday, so I'm gonna have to buy it. $60, damn. Graphically it is, without a doubt, the most beautiful game I have ever seen. Its gameplay is utterly consuming. I may not be sleeping much these next few weeks.
On coming to the surface (the game starts underground), an incredible panorama opens. The trees, the normal/gloss mapping of the rocks, the water. Everything looks amazing. The world is massive beyond belief. A profound sense of freedom - you can do anything. Playing Oblivion for the first time was very much like opening up the exquisite world of Ultima V as a kid. Few games appeal to me that much.
For me, it is essential that a game inspire a sense of freedom with Ultima V, Times of Lore, GTA III, Spider-Man 2 being representative examples.
On coming to the surface (the game starts underground), an incredible panorama opens. The trees, the normal/gloss mapping of the rocks, the water. Everything looks amazing. The world is massive beyond belief. A profound sense of freedom - you can do anything. Playing Oblivion for the first time was very much like opening up the exquisite world of Ultima V as a kid. Few games appeal to me that much.
For me, it is essential that a game inspire a sense of freedom with Ultima V, Times of Lore, GTA III, Spider-Man 2 being representative examples.
Tuesday, May 23, 2006
Data Access Latency
Ryan and I have talked about making a chart to easily visualize the relative costs of common computer operations. A significant part of this is data access latencies in modern computer hardware. Yesterday I stumbled across some numbers in Raymond Chen's PDC 05 Talk: Five Things Every Windows Programmer Should Know, and behold! a chart is born:
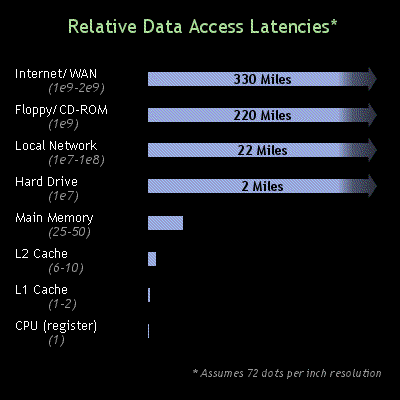
Main memory latency has become a crucial consideration in modern software development. As the processor (CPU in the chart) becomes faster, the gulf between the processor memory (registers and caches) and main memory latency widens, making cache misses increasingly more expensive with respect to processor cycles. An increasingly frequent software design decision is to use simple array based data structures as opposed to pointer based tree and list structures for many operations. Typically, pointer structures (linked lists, binary trees, etc.) are theoretically more efficient than their linear counterparts (for example, binary trees [O(lg n) vs. O(n)] vs. linear search). Given the high cost of cache misses in modern hardware and the good memory locality of array based approaches, pointer based structures may perform 25-100 times more poorly than their simpler counterparts. In developing for the Xbox 360 and PlayStation 3 with crazy powerful processors, linearizing data structures is a crucial optimization.
So instead of using that binary tree next time, consider using a sorted linear array with a binary search.
{kind=link}

Main memory latency has become a crucial consideration in modern software development. As the processor (CPU in the chart) becomes faster, the gulf between the processor memory (registers and caches) and main memory latency widens, making cache misses increasingly more expensive with respect to processor cycles. An increasingly frequent software design decision is to use simple array based data structures as opposed to pointer based tree and list structures for many operations. Typically, pointer structures (linked lists, binary trees, etc.) are theoretically more efficient than their linear counterparts (for example, binary trees [O(lg n) vs. O(n)] vs. linear search). Given the high cost of cache misses in modern hardware and the good memory locality of array based approaches, pointer based structures may perform 25-100 times more poorly than their simpler counterparts. In developing for the Xbox 360 and PlayStation 3 with crazy powerful processors, linearizing data structures is a crucial optimization.
So instead of using that binary tree next time, consider using a sorted linear array with a binary search.
Thursday, May 18, 2006
class vs. struct
As C++ interviewees know well, the only difference between class and struct in C++ is that class defaults to an access mode of private and struct defaults to public. This means that the difference between them is purely syntactic and has no semantic connotation whatsoever. Because of this, some C++ experts believe that the struct keyword should not be used at all and we should always use class { public: instead.
So why do developers continue to use both when there is no semantic difference? To people, struct and class communicate subtly different ideas. Developers often use the struct keyword (because of its C heritage) to indicate a lightweight, open record that is not encapsulated. For example, a small record intended to be written directly to a file is more likely to be a struct in these situations. The class keyword is then used for traditional C++ object orientation. The fascinating thing about this dichotomy is that even computer language keywords develop nuances of meaning apart from their original intent.
So why do developers continue to use both when there is no semantic difference? To people, struct and class communicate subtly different ideas. Developers often use the struct keyword (because of its C heritage) to indicate a lightweight, open record that is not encapsulated. For example, a small record intended to be written directly to a file is more likely to be a struct in these situations. The class keyword is then used for traditional C++ object orientation. The fascinating thing about this dichotomy is that even computer language keywords develop nuances of meaning apart from their original intent.
Formatting std::string
The following snippet has been a part of my personal code library for years. It is useful for formatting a std::string in a traditional printf() way. For all its ills, printf/sprintf() is incredibly convenient. This code is for Win32. Minor modification is required for Unix.
#include <stdio.h>
#include <stdarg.h>
#include <string>
std::string format_arg_list(const char *fmt, va_list args)
{
if (!fmt) return "";
int result = -1, length = 256;
char *buffer = 0;
while (result == -1)
{
if (buffer) delete [] buffer;
buffer = new char [length + 1];
memset(buffer, 0, length + 1);
result = _vsnprintf(buffer, length, fmt, args);
length *= 2;
}
std::string s(buffer);
delete [] buffer;
return s;
}
std::string format(const char *fmt, ...)
{
va_list args;
va_start(args, fmt);
std::string s = format_arg_list(fmt, args);
va_end(args);
return s;
}
Monday, May 15, 2006
Muddy Waters
A fascinating view of anti-pattern/pattern Big Ball of Mud and its relatives. Big Ball of Mud is the kind of horrifically structured software we have all seen and shunned throughout our careers. Software of this sort is not just poorly architected, but lacks any architecture whatsoever. Nevertheless, the authors argue, when an approach is so pervasive and universal as this one is, there must be something it does well.
Citing shanty towns as an instance of the Big Ball of Mud pattern, the authors say:
Shantytowns emerge where there is a need for housing, a surplus of unskilled labor, and a dearth of capital investment. Shantytowns fulfill an immediate, local need for housing by bringing available resources to bear on the problem. Loftier architectural goals are a luxury that has to wait.
Traditionally good architecture in software dramatically reduces maintenance requirements and failure rates. Values that traditional software architecture respect are robustness, maintainability/low cost of maintenance, performance and efficiency. To achieve these goals, the development of such software requires software architects (not cheap), more sophisticated (and therefore more expensive) developers, and, in general, more development time.
In contrast the Big Ball of Mud development style values low cost of initial development and is willing to achieve that by accepting a relatively high cost of continuing maintenance as its solutions are not robust. It requires no architects, far less skilled developers and less initial development time. However, it may also require a larger dedicated maintenance staff.
Citing shanty towns as an instance of the Big Ball of Mud pattern, the authors say:
Shantytowns emerge where there is a need for housing, a surplus of unskilled labor, and a dearth of capital investment. Shantytowns fulfill an immediate, local need for housing by bringing available resources to bear on the problem. Loftier architectural goals are a luxury that has to wait.
Traditionally good architecture in software dramatically reduces maintenance requirements and failure rates. Values that traditional software architecture respect are robustness, maintainability/low cost of maintenance, performance and efficiency. To achieve these goals, the development of such software requires software architects (not cheap), more sophisticated (and therefore more expensive) developers, and, in general, more development time.
In contrast the Big Ball of Mud development style values low cost of initial development and is willing to achieve that by accepting a relatively high cost of continuing maintenance as its solutions are not robust. It requires no architects, far less skilled developers and less initial development time. However, it may also require a larger dedicated maintenance staff.
Urbanization
Because I enjoy creating games on my own time and am attracted to the sort of open world games described in the previous post, I'm interested in automatic generation of urban landscapes for games. There is no way I can create an entire city such as the cities of GTA or Ultimate Spider-Man without a high level of automation. I've seen some work in this area, most of which is concerned with generating low-detail cities in real-time. I'm interested in offline high-detail content creation.
From 2004 to early 2005 I developed a pair of programs to accomplish this. The first of these is pov2mesh, a program that converts a constructive solid geometry (CSG) file (Pov-Ray format) into a Maya vector .obj file. The second of these is Urbia which generates the CSG file from an abstract .xml definition of the world, fills in the blanks and invokes pov2mesh to complete the conversion to .obj. The pov2mesh application is currently offered as shareware on my site. I also plan to offer Urbia as shareware when it's more polished.
See this for a discussion of pov2mesh's future and feasiblity.
From 2004 to early 2005 I developed a pair of programs to accomplish this. The first of these is pov2mesh, a program that converts a constructive solid geometry (CSG) file (Pov-Ray format) into a Maya vector .obj file. The second of these is Urbia which generates the CSG file from an abstract .xml definition of the world, fills in the blanks and invokes pov2mesh to complete the conversion to .obj. The pov2mesh application is currently offered as shareware on my site. I also plan to offer Urbia as shareware when it's more polished.
See this for a discussion of pov2mesh's future and feasiblity.

A city block generated by Urbia for my game in progress Cuervo.
(Updated 7/10/07)
Here are some great links passed on from an EA guy who went to SIGGRAPH 06-
Subscribe to:
Comments (Atom)